DiPOD: Diffusion Policy Optimization without Drifting Apart
Diffusion language models are an exciting alternative to autoregressive language models. Instead of generating a response strictly left-to-right, they can refine many tokens in parallel. This opens the door to faster sampling, flexible decoding orders, and possibly new ways of doing long-form reasoning.
But there is a gap between this promise and the current reality. Reinforcement learning (RL), especially policy-gradient methods, has become one of the main reasons modern autoregressive LLMs got much better at math, code, and instruction following. For diffusion language models, however, RL post-training has not paid off in the same way. Training is often unstable, reward curves wobble, and reasoning performance still lags behind autoregressive counterparts.
In our paper ([1]), we identify this problem as double drift. The first drift happens on the diffusion-modeling side: the variational bound used as a likelihood proxy can drift away from the true log-likelihood. The second drift happens on the RL side: once the proxy is loose, the resulting proxy gradient can drift away from the true policy gradient of expected return.
We then propose DiPOD, short for Diffusion Policy Optimization without Drifting apart. DiPOD is a framework for reasoning about this failure mode and solving it.
This blog explains the idea with much less machinery than the paper.
What is Wrong with Existing Approaches?
Let us start with the policy gradient theorem. In reinforcement learning, we have a policy $\pi_\theta$ that takes an observation $o$ and samples an action $a$. The goal is to adjust $\theta$ so that the expected reward improves.
Most policy-gradient methods are built around an update of the following form:
$$ \mathbb{E}\left[ \hat A(o,a)\nabla_\theta \log \pi_\theta(a|o) \right]. $$Here $\hat A(o,a)$ is the estimated advantage. If $\hat A(o,a)>0$, the action did better than expected, so the update should make it more likely. If $\hat A(o,a)<0$, the action did worse than expected, so the update should make it less likely.
The problem is the term
$$ \log \pi_\theta(a|o). $$In language models, $o$ can be thought of as the prompt or current context, and $a$ as the generated response. For autoregressive language models, $\log \pi_\theta(a|o)$ is easy to compute: the probability of a sequence is the product of next-token probabilities. For diffusion models, sampling can be easy while exact likelihood computation is generally intractable. A lot of existing diffusion RL algorithms1 are, in spirit, trying to do the same thing: replace the missing $\log \pi_\theta$ term with a tractable diffusion training objective. The most natural candidate is the ELBO.
1 The paper's analysis applies similarly to diffusion policies and flow policies. We mostly use "diffusion" in this blog to keep the exposition light; the distinction does not affect the analysis.
The Variational Inference Approach
A natural replacement for the log-likelihood is the ELBO, the evidence lower bound. ELBO is attractive because it is tractable, it is already the usual variational objective behind diffusion model pretraining, and in a well-trained diffusion model it can be tight.
The key relation is
$$ \begin{aligned} \mathrm{ELBO}_\theta(a|o)=\log \pi_\theta(a|o)-\mathcal D_\theta^{L}(o,a), \end{aligned} $$where $\mathcal D_\theta^{L}(o,a)\ge 0$ is the gap between the ELBO and the true log-likelihood. When the diffusion model is perfectly trained, this gap becomes zero, so
$$ \mathrm{ELBO}_\theta(a|o)=\log \pi_\theta(a|o). $$This is also the objective we use in pretraining. Diffusion models are usually pretrained through maximizing
$$ \mathbb{E}_{(o,a)\sim p_{\mathrm{data}}} \left[ \mathrm{ELBO}_\theta(a|o) \right]. $$When the model is perfectly trained, the ELBO becomes tight. This is why ELBO-based RL is tempting. We cannot compute the exact likelihood, but we can compute a bound that is supposed to match it when the diffusion model is behaving nicely.
This point matters especially for post-training. Before RL begins, we usually start from a pretrained diffusion model. Pretraining has already pushed the model to maximize ELBO on data, so the bound is often tight, or at least locally close to tight, near the initialization. That makes ELBO feel like a principled stand-in for $\log \pi_\theta$ at the beginning of RL.
Many algorithms live in this general spirit of replacing $\log \pi_\theta$ with an ELBO-like quantity. FPO ([2]) is a representative example. Up to PPO-style clipping for stability, it replaces the log-likelihood gradient in policy gradient with the ELBO gradient:
$$ \begin{aligned} g_\theta^{\mathrm{FPO}}(o,a) &= \hat A(o,a)\nabla_\theta \mathrm{ELBO}_\theta(a|o). \end{aligned} $$If the ELBO is close to the true log-likelihood, this looks reasonable. Positive-advantage samples get higher ELBO. Negative-advantage samples get lower ELBO. This feels like the diffusion analogue of making good actions more likely and bad actions less likely.
But by itself this replacement lacks a guarantee. There is a hidden problem.
The ELBO Can Cheat
Because
$$ \begin{aligned} \mathrm{ELBO} = \log \pi - \mathcal D^{L}, \end{aligned} $$changing the ELBO does not tell us exactly what happened to the likelihood. An ELBO increase could mean the true likelihood increased. It could also mean the discrepancy $\mathcal D^{L}$ decreased while the true likelihood stayed the same or even moved in the wrong direction.
The issue is especially sharp for negative advantages.
Suppose an action receives negative advantage. We want to make this action less likely. An ELBO-based update tries to decrease
$$ \mathrm{ELBO}_\theta(a|o). $$But there are two ways to do that:
- Decrease $\log \pi_\theta(a|o)$.
- Increase the discrepancy $\mathcal D_\theta^{L}(o,a)$.
Only the first one is what RL wants. The second one is a loophole. The model can lower the ELBO by making the variational bound looser, without actually reducing the likelihood of the bad action in the intended way. In plain language, the ELBO can “cheat” by damaging the diffusion model structure instead of improving the policy.
SPG’s Fix
A remedy that works particularly well for diffusion language models is SPG. SPG improves on this story by noticing that negative advantages should be handled differently. Since the ELBO is a lower bound on the log-likelihood, it is natural for positive advantages. For negative advantages, SPG uses a variational upper bound, called the EUBO:
$$ \begin{aligned} \mathrm{EUBO}_\theta(a|o) = \log \pi_\theta(a|o) + \mathcal D_\theta^{U}(o,a), \end{aligned} $$where $\mathcal D_\theta^{U}(o,a)\ge 0$.
The SPG update uses ELBO for positive advantages and EUBO for negative advantages:
$$ \begin{aligned} g_\theta^{\mathrm{SPG}}(o,a) = \mathbf 1_{\hat A>0} \hat A\nabla_\theta \mathrm{ELBO}_\theta(a|o)+ \mathbf 1_{\hat A<0} \hat A\nabla_\theta \mathrm{EUBO}_\theta(a|o). \end{aligned} $$This is a real improvement. Because EUBO is an upper bound, using it with negative advantages gives a true lower-bound interpretation of the policy-gradient objective. In other words, SPG repairs the most obvious “wrong bound for the sign” problem in ELBO-as-log-likelihood updates, and this is one reason it is strong in diffusion language model post-training.
But two issues remain.
First, EUBO is itself intractable in general, so practical SPG uses approximations that are specialized to certain diffusion language model settings.
Second, and more importantly for our paper, an objective-level lower bound does not automatically imply that each gradient step is aligned with the true policy gradient. The bound may become exact at the optimum, but RL training is not only about what happens at the optimum. It is about the sequence of updates that gets us there.
The algorithms mentioned above are not just special instances. Instead, they reveal a more general question: can variational proxies be trusted as policy-gradient proxies at all, and if so, how can we maintain that trust throughout the whole post-training trajectory?
At this point, one may wonder: why did we take the variational inference perspective in the first place? There are deeper reasons to take this route beyond the local tightness of the bound. We return to this more holistic view after introducing DiPOD.
The Double Drift Problem
The broad class of variational-proxy methods is not arbitrary. These methods often work well at the beginning of training. This is important, because it tells us the idea is not completely wrong.
The reason goes back to pretraining. We usually start from a diffusion model that was trained with an ELBO-style objective. Around this initialization, the variational bound is often tight, or at least close to tight. This is where the variational proxy earns its initial trust.
If the bound is tight, then
$$ \mathrm{ELBO}_\theta(a|o)=\log \pi_\theta(a|o), $$which means the discrepancy $\mathcal D_\theta^{L}(o,a)$ is zero. Since this discrepancy is nonnegative and minimized at zero, tightness also implies, under the usual smoothness assumption,
$$ \nabla_\theta \mathrm{ELBO}_\theta(a|o)=\nabla_\theta \log \pi_\theta(a|o). $$In practice, the pretrained model may not be mathematically perfect, but if the bound is locally close to tight, the ELBO gradient can be close to the likelihood gradient. So the proxy gradient can initially point in the right direction. This explains why FPO- and SPG-style variational diffusion RL methods can show real reward improvement early in training.
The problem is what happens after the policy starts moving.
RL updates are reward-seeking. They are not automatically structure-preserving. As the model is pushed toward actions with higher reward, nothing guarantees that the ELBO remains tight. The discrepancy term can grow. Once it grows, the proxy starts drifting away from the quantity it is supposed to approximate.
This gives the first drift:
ELBO-likelihood drift: the variational bound separates from the true log-likelihood.
Then the second drift follows. From the ELBO identity,
$$ \begin{aligned} \nabla_\theta \mathrm{ELBO}_\theta = \nabla_\theta \log \pi_\theta - \nabla_\theta \mathcal D_\theta^{L}. \end{aligned} $$When the discrepancy is small, the extra term is harmless. When the discrepancy grows, the update is no longer just a likelihood update. Part of the gradient is now spent changing the variational gap.
This gives the second drift:
Policy-gradient drift: the proxy gradient separates from the true policy gradient of expected return.
Together, these form the double drift phenomenon. The diffusion-model side drifts first: the evidence bound becomes loose. Then the RL side drifts with it: the gradient no longer reliably follows the policy-improvement direction.
In the paper we formalize this with a theory of adequate estimators and on-policy tightness. For the blog, the main takeaway is simpler:
Variational diffusion RL methods can be good near a pretrained model, but RL training can move the model out of the regime where their gradients are trustworthy.
So instead of only asking, “which likelihood proxy should we use?”, we should also ask, “how do we keep the proxy valid while training?”
DiPOD: Keep the Bound Tight While Improving the Policy
DiPOD is built around two design principles.
- Policy improvement: the algorithm should increase the expected return of the policy on the downstream task.
- Tight ELBO: after fine-tuning, the policy should remain a valid diffusion model; requiring the ELBO to remain tight is a natural way to preserve this structure.
The first principle is the RL goal. The second is the diffusion-modeling constraint. DiPOD is designed to satisfy both during training.
Concretely, DiPOD interleaves two steps.
First, do a self-distillation step. Take rollouts from the current policy and maximize the ELBO on those rollouts. This tightens the bound on the distribution the policy is actually visiting. In the ideal case, this step changes the internal diffusion representation so that the ELBO becomes tight, while preserving the policy’s output distribution.
Second, do a policy-gradient step using an estimator that is correct when the bound is tight. Since the self-distillation step has just restored tightness, this update is again a meaningful policy-improvement step.
Then repeat:
- Tighten the bound on-policy.
- Take a policy-improving update.
- Refresh the reference policy.
- Tighten again.
This is the conceptual DiPOD framework. It is not tied to one particular estimator. FPO-style and SPG-style gradients can both be used inside the framework, as long as they are accurate in the tight-bound regime. The framework is the main point: it gives a way to reason about which proxy gradients are trustworthy and how to keep them trustworthy as RL moves the policy.
The Practical Version
The interleaving picture is the clean principle, but running self-distillation to convergence before every policy update would be expensive. We therefore introduce an implementation that requires minimal change to the base algorithm.
The connection is to absorb a small self-distillation step into each policy update. In a standard diffusion RL update, we take a batch of rollouts $(o^i,a^i)$ and update with some diffusion policy-gradient estimator $g_\theta(o^i,a^i)$. DiPOD uses the same rollout batch for the base policy-gradient estimator and for an ELBO maximization term:
$$ \begin{aligned} \theta\leftarrow \theta+ \eta\frac{1}{m}\sum_{i=1}^{m}\Bigl[g_\theta(o^i,a^i) + \beta\nabla_\theta\mathrm{ELBO}_\theta(a^i|o^i)\Bigr]. \end{aligned} $$Here $m$ is the number of rollout samples in the batch, and $\beta>0$ controls how strongly we weight the on-policy ELBO regularization term.
This can be viewed as a first-order approximation to interleaving self-distillation and policy improvement on every rollout batch. The new term does a small amount of self-distillation on the same data used for RL. It encourages the model to keep the ELBO high on the actions the current policy actually samples. Equivalently, it pushes down the variational discrepancy on-policy.
This is why DiPOD is better thought of as a framework rather than a single algorithm. It says:
Take the diffusion policy-gradient method you already use, then add a mechanism that keeps the variational bound tight along the training trajectory.
In our simplest implementation, that mechanism is just the extra ELBO term. Relative to the base algorithm, the update only changes by adding this regularizer.
Experiments
We test DiPOD in three settings: a controlled toy problem, diffusion language model post-training, and diffusion policies for motion tracking.
A Toy Experiment
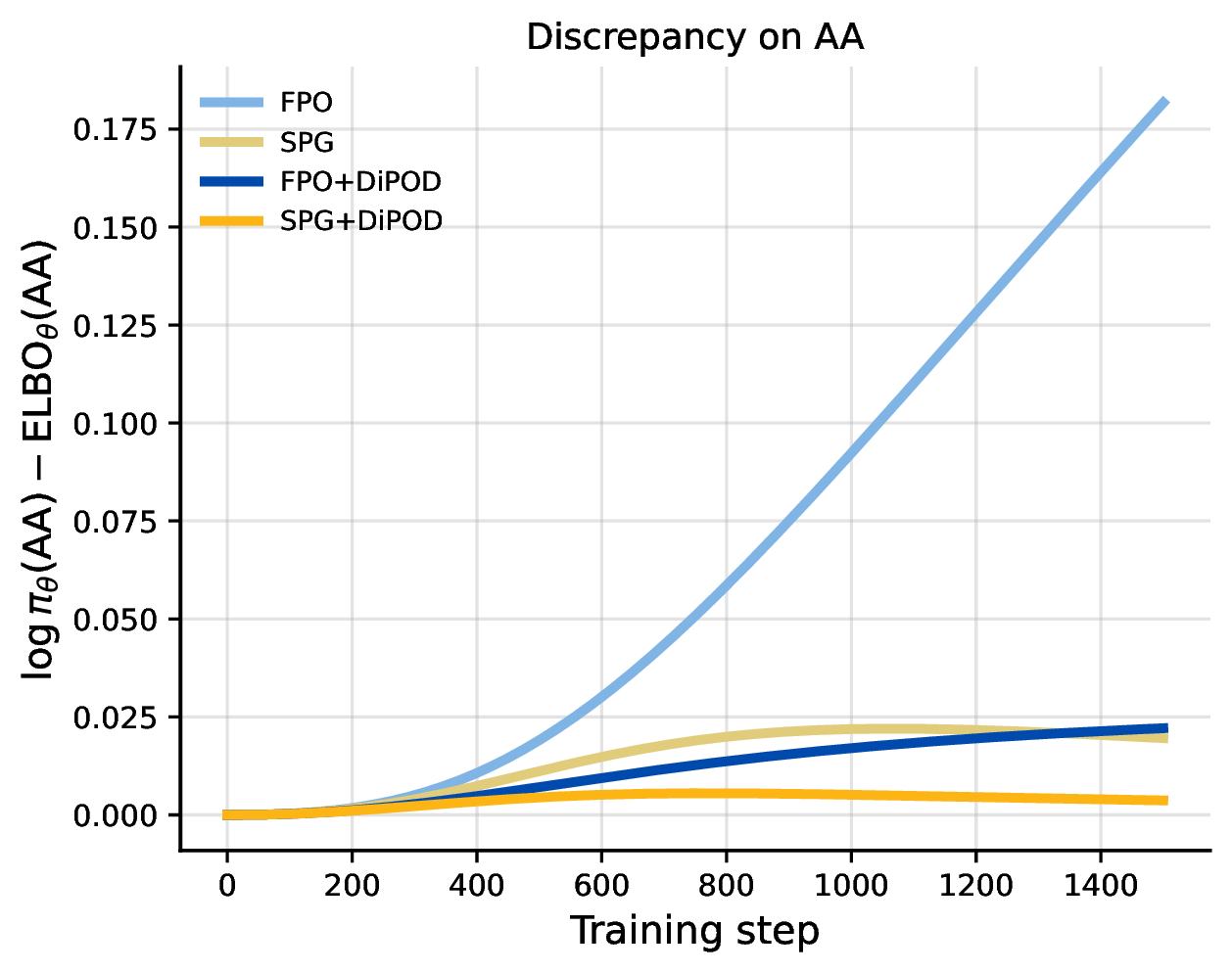
First, we use a two-token diffusion model where the whole state space is small enough to enumerate. This lets us compute the true log-likelihood, the ELBO, and the gap between them throughout training.
The result shows the drift of ELBO explicitly. Under FPO, the variational gap grows substantially as training proceeds. SPG controls the gap better, but the gap is still present. Adding DiPOD keeps the gap much more controlled.
Reasoning with Diffusion Language Models
Next, we apply DiPOD to RL post-training of LLaDA-8B-Instruct on four reasoning benchmarks:
- GSM8K
- MATH500
- Countdown
- Sudoku
We evaluate DiPOD on top of both FPO-style and SPG-style updates. In the language experiments, we keep the DiPOD coefficient fixed at $\beta=0.05$ across tasks.
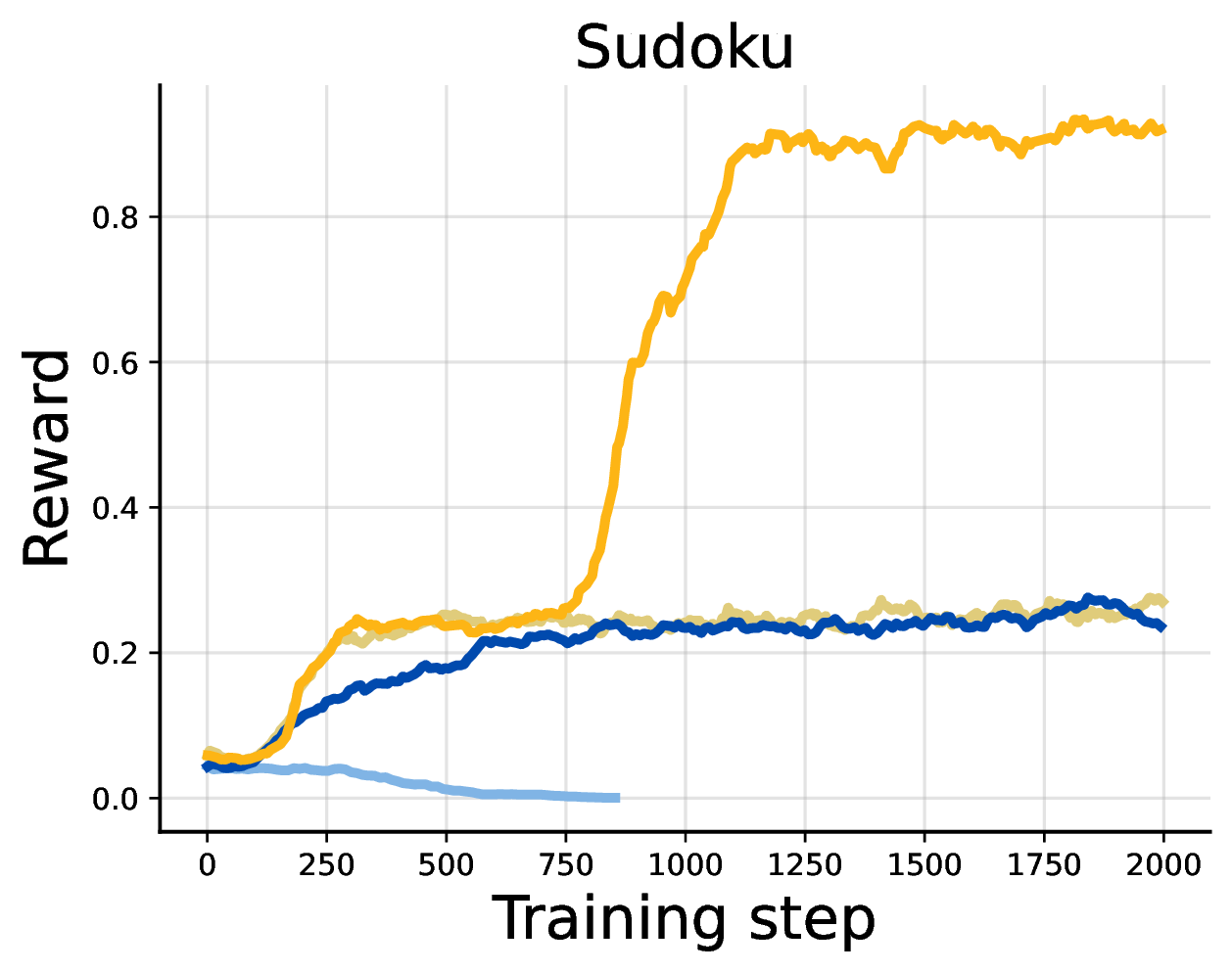
The pattern is consistent. FPO+DiPOD improves over FPO. SPG+DiPOD improves over SPG or remains competitive on math reasoning, and gives especially large gains on logical reasoning tasks such as Countdown and Sudoku.
The Sudoku result is particularly striking: SPG+DiPOD saturates the benchmark in the zero-shot setting. This is a useful sign that the missing ingredient was not only model scale or pretraining strength. Stabilizing the RL dynamics matters.
For GSM8K and MATH500, the gains are more modest. Our current hypothesis is that the fixed context window of diffusion language models becomes a bottleneck for harder math problems that require long chains of thought. DiPOD helps the optimization, but it does not remove architectural or inference-budget limits.
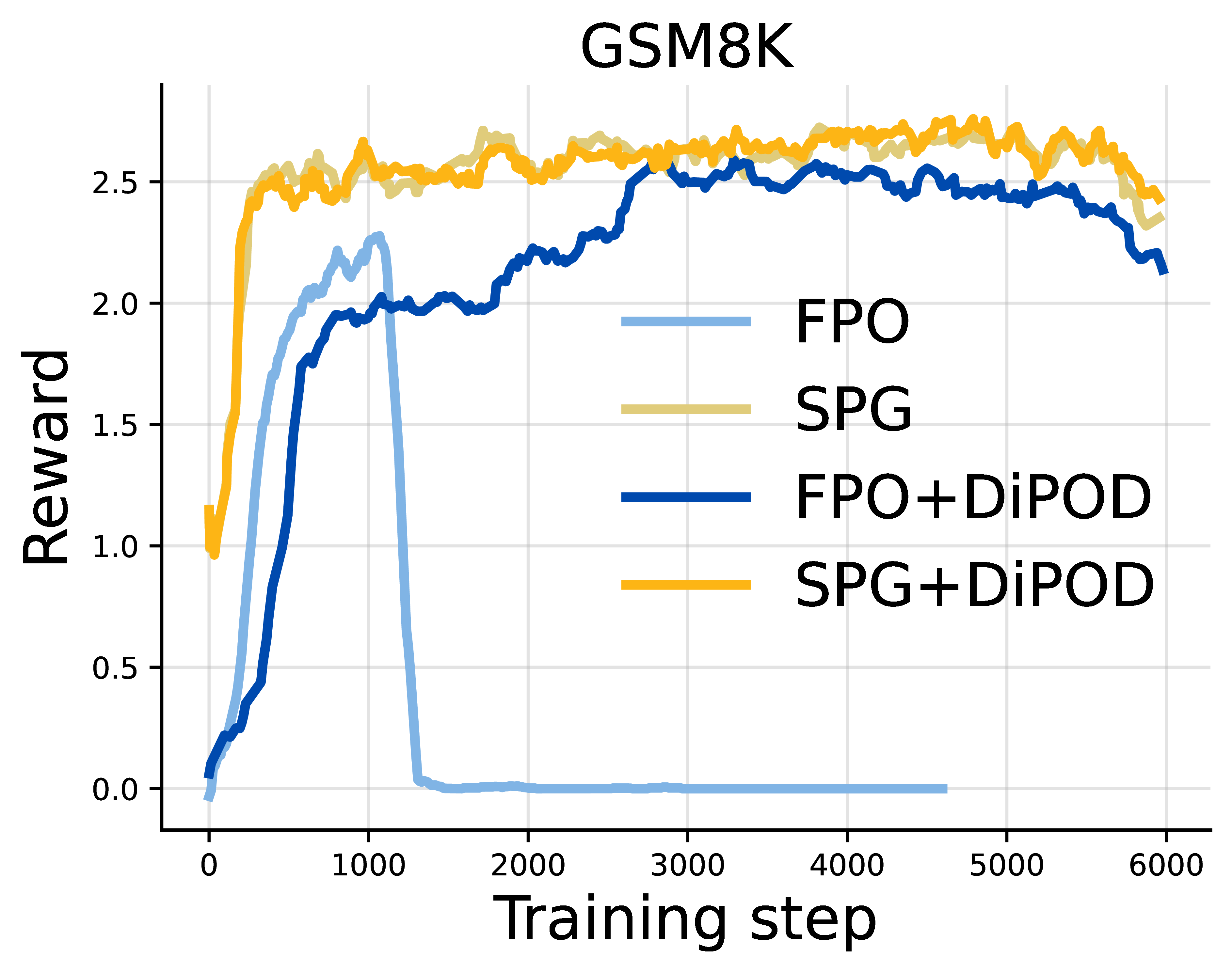
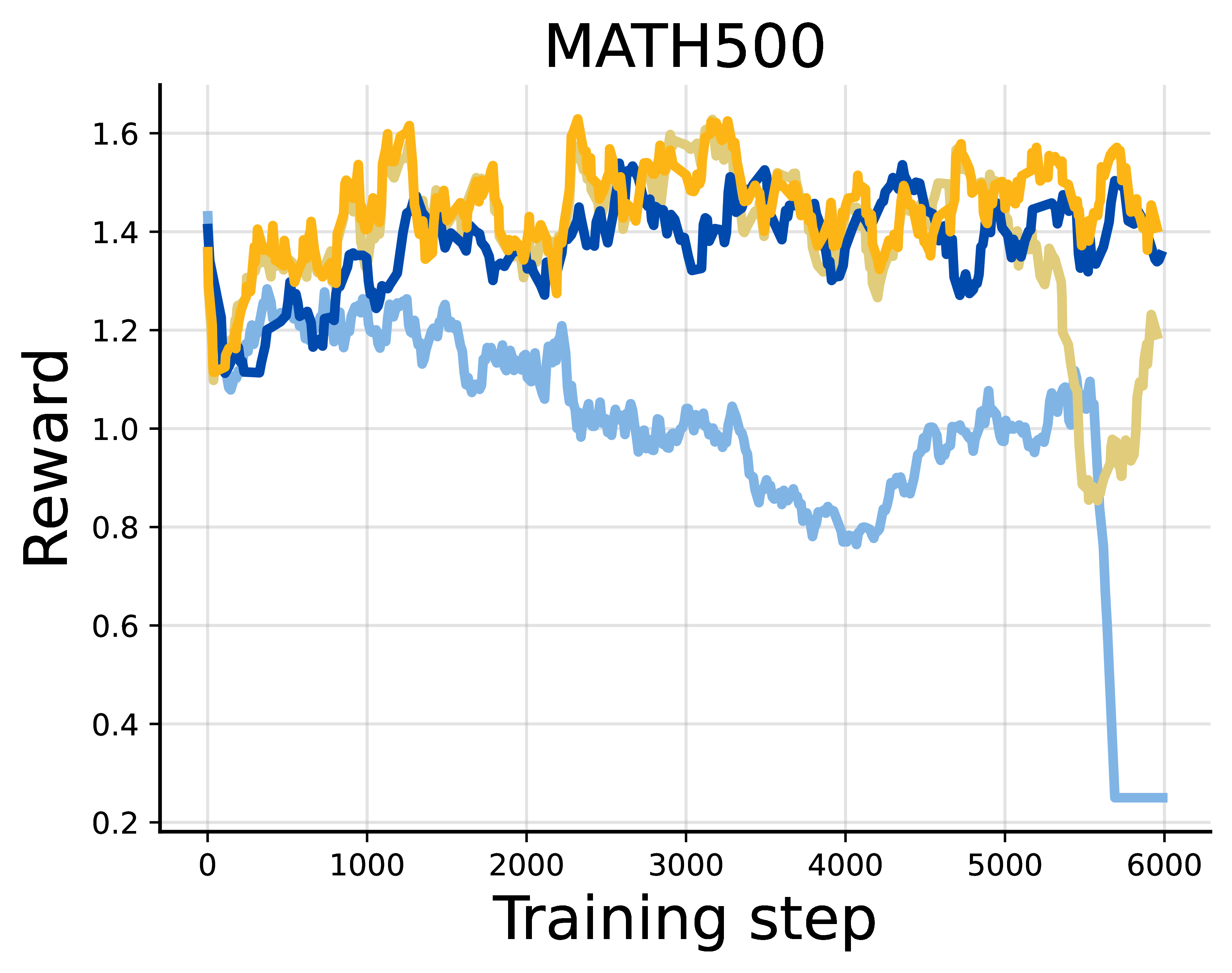
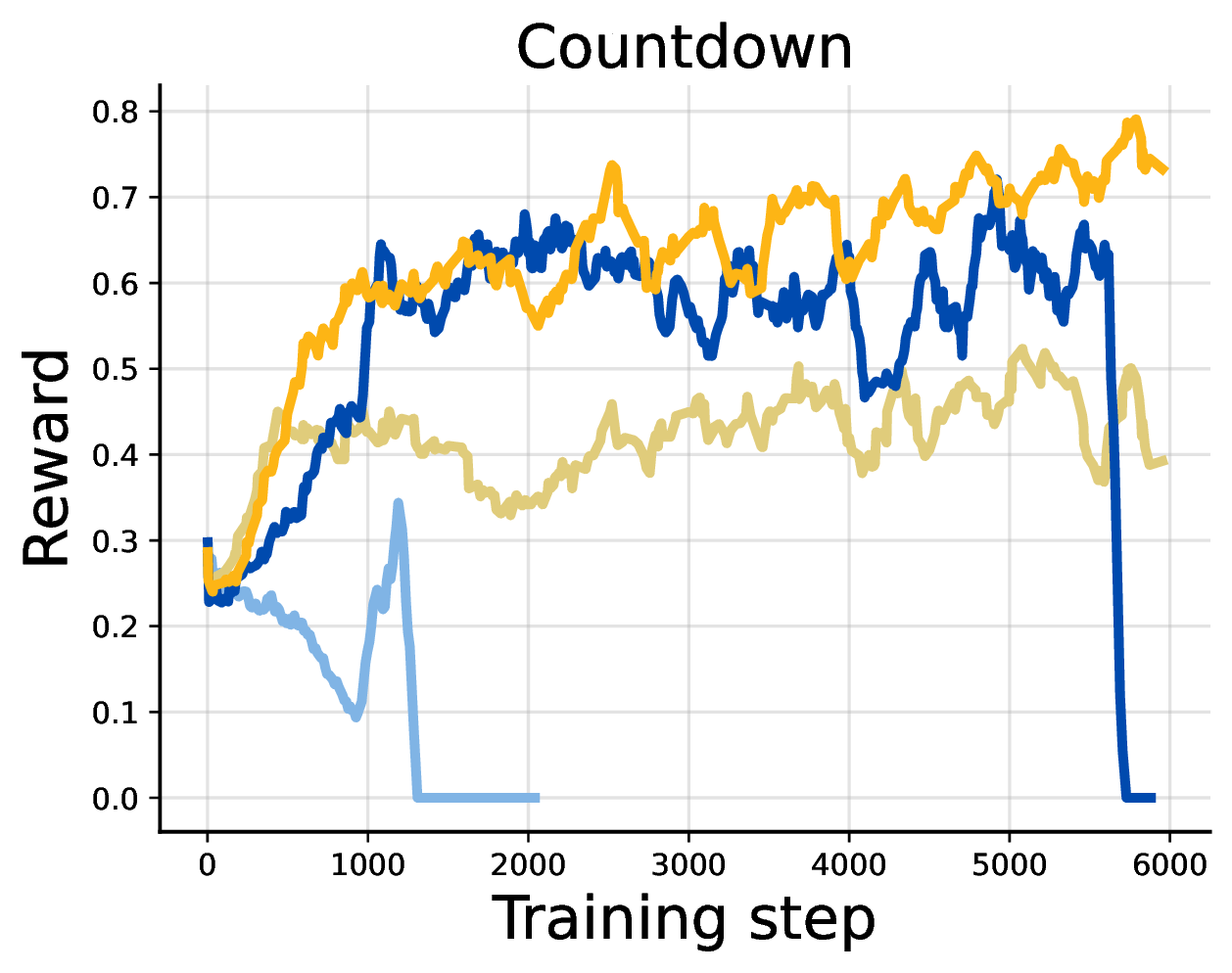
Motion Tracking
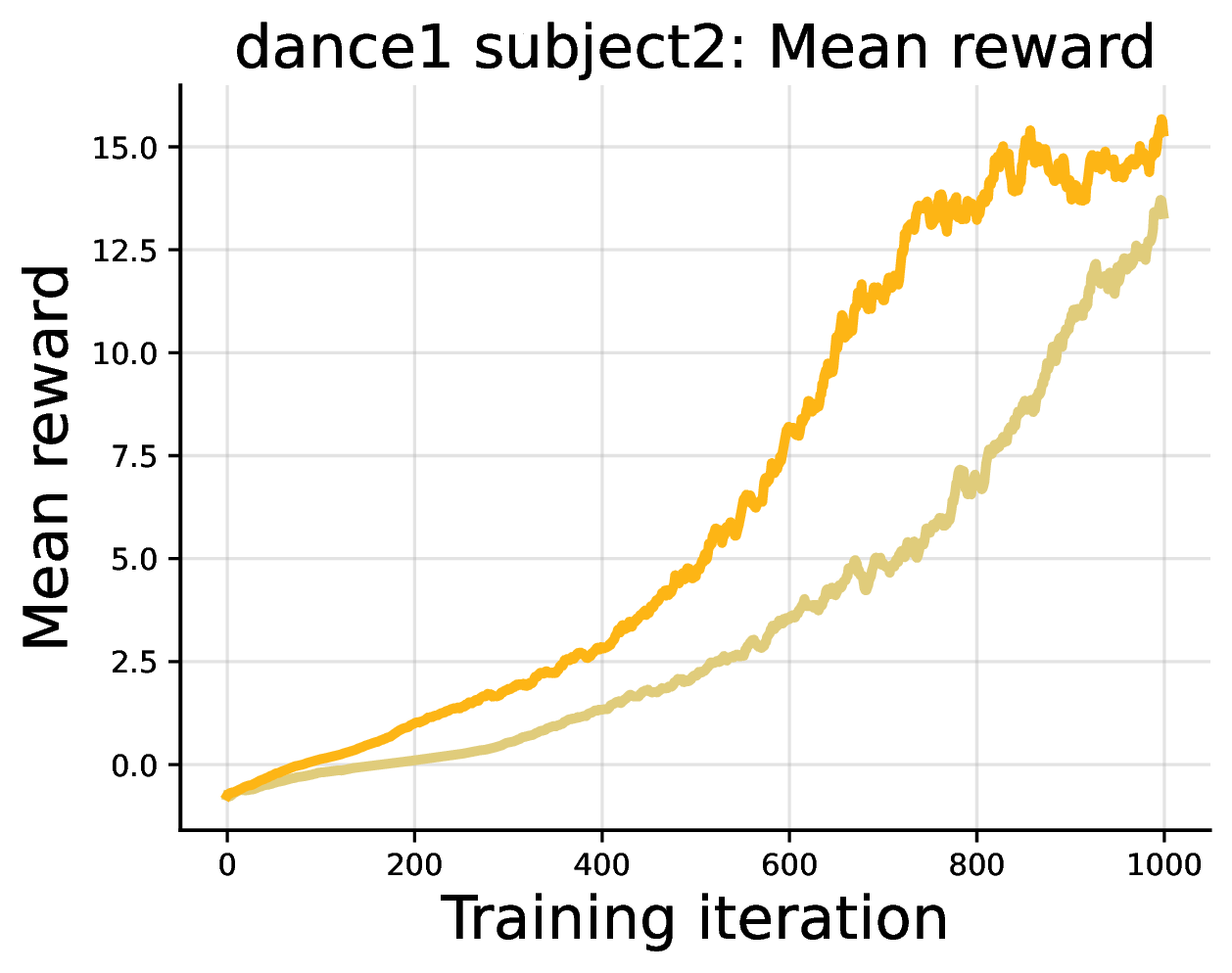
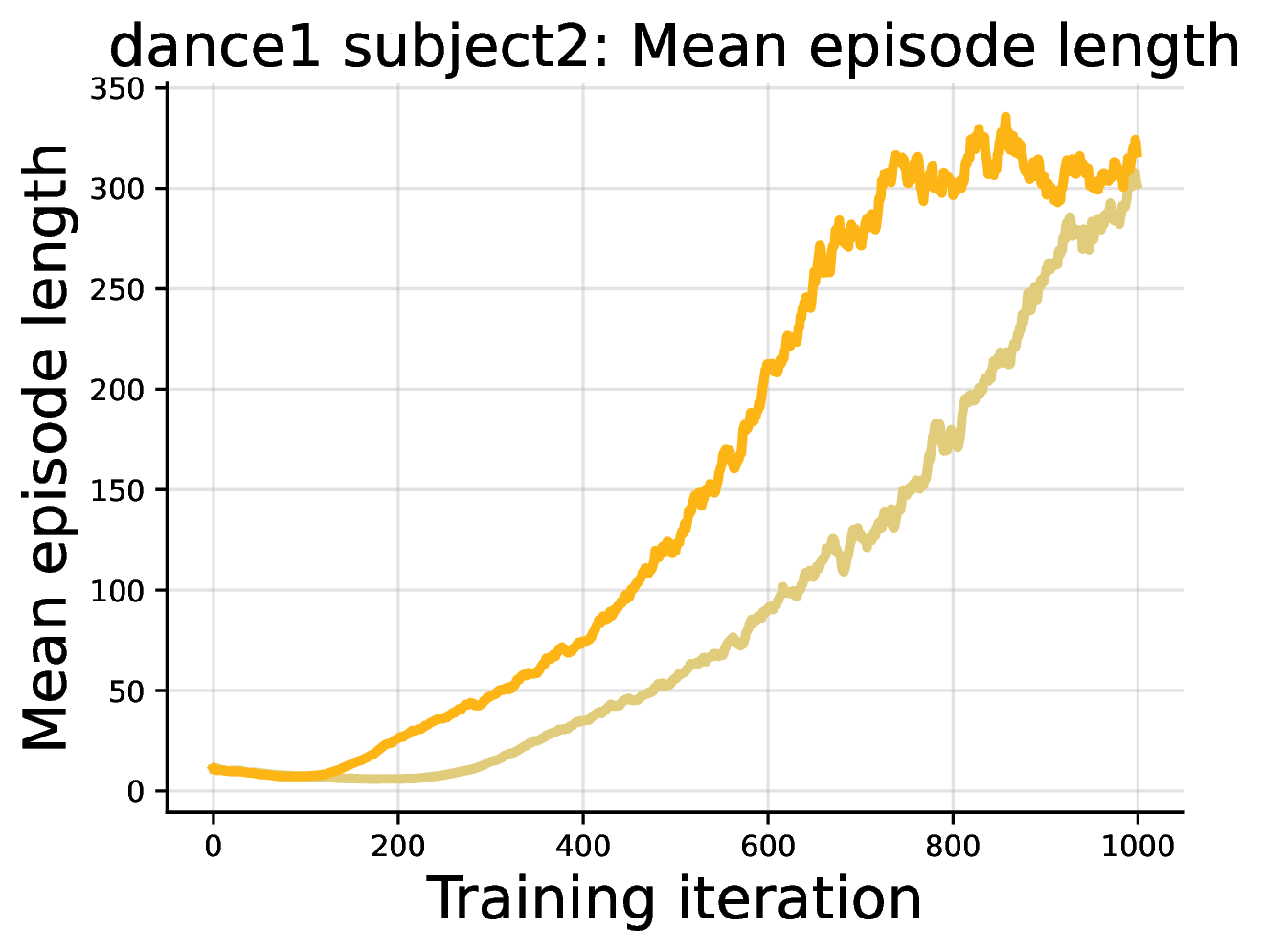
DiPOD is not only a trick for diffusion language models. We also test the principle in continuous control, using a diffusion or flow policy for humanoid motion tracking.
We use FPO++, an improved FPO-style algorithm for flow policies. It is not identical to the FPO update discussed above, but it can be understood in the same mental model: policy-gradient training relies on a tractable variational proxy for the intractable likelihood. Unlike the LLaDA experiments, motion tracking trains the policy for the task from the beginning, so we use a minimal DiPOD instantiation: one self-distillation stage to tighten the ELBO-likelihood gap, followed by the usual FPO++ policy-gradient training. In spirit, this is DiPOD with a single tightening cycle before RL begins.
The policy controls a Unitree G1 humanoid to track reference motions, and DiPOD improves reward dynamics and tracking duration over the reproduced FPO++ baseline. See the paper for the full motion-tracking setup and results.
Why Take the Variational Route?
Let us now return to the question we postponed earlier: why take a variational approach at all? The paper focuses on diffusion RL algorithms that aim to satisfy two design principles:
- Policy improvement. The algorithm should increase the expected return of the policy on the downstream task. This is the basic goal of RL post-training.
- Generative-model preservation. After fine-tuning, the policy should remain a valid diffusion model. More specifically, we require that the ELBO is tight after RL. For flow models, this is equivalent to having a zero conditional flow matching loss.
While the first principle is straightforward, the second one is more subtle. The basic reason that the second principle is important is that when training a policy, one chooses a generative model that best fits the needs of the task. It is natural to want to keep the structure chosen in the first place after RL. This argument is not just about diffusion models, and it further applies to other generative models as well. A lot of generative models can be formalized in the form of variational inference, and the discrepancy between ELBO and log likelihood reflects how far the model is from the intended structure prescribed by the generative model family.
We acknowledge that its practical relevance may depend on the specific application. Concretely, we provide several examples:
- In language models, diffusion provides us with the flexibility to decode in any order, and to set different inference time budgets. These require a tight ELBO.
- In protein design, people often do classifier guidance on a discrete diffusion model. Proper classifier guidance requires a perfectly learned score function, and equivalently, a tight ELBO.
- In a lot of applications of motion tracking in robotics, people may choose diffusion models because they can handle multimodality from initialization, but they ultimately only care about the final performance. In this case, the second principle becomes unnecessary. However, if one chooses to use a variational algorithm for other reasons, one would still want the ELBO to remain tight throughout training due to the double drift issue.
Under the two principles we just established, adopting the variational inference perspective becomes straightforward. Besides the variational methods, we examine several other lines of work under the two principles for contrast.
MDP-based methods. A natural way to avoid the intractable likelihood is to treat the denoising process itself as an MDP, as in DDPO ([7]) and DPPO ([8]). Under this formulation, the policy gradient becomes direct, so the policy-improvement principle is satisfied in the usual RL sense. The cost is that the effective horizon is lengthened by the number of denoising steps, which can make credit assignment harder and increase variance. Moreover, the second principle is essentially broken: the algorithm optimizes a sampler-specific denoising MDP rather than maintaining a tight likelihood proxy for the final diffusion policy. This also removes one of the main attractions of diffusion models, namely the flexibility to choose different decoders, samplers, or inference budgets after training.
Direct approximation methods. This line appears frequently in diffusion language models, where likelihoods are approximated by mean-field estimates, one-step estimates, partial dependency restoration, or imposed autoregressive orders. Examples include d1 ([4]), Dream-Coder ([9]), and wd1 ([10]). These approximations make training tractable, but they usually cannot become exactly tight with the true diffusion likelihood. In language, they also tend to break or simplify inter-token dependencies, which makes the optimized proxy policy different from the diffusion policy we actually execute. Under the first principle, this means policy improvement is only with respect to the approximation, not necessarily the original diffusion policy. Under the second principle, there is no guarantee that the generative structure or tight ELBO behavior is preserved.
Stochastic-optimal-control methods. A different line, such as Adjoint Matching ([6]), takes a stochastic-optimal-control view of fine-tuning diffusion or flow models. This perspective is elegant: under its assumptions, it can target the desired tilted distribution and preserve the generative process, so it is compatible with both principles. The limitation is practical scope. These methods typically require differentiable rewards or a learned critic/$Q$-function, while the online policy-gradient setting we focus on often involves non-differentiable rewards, such as exact answer checks in reasoning tasks.
Conclusion
DiPOD is not just a simple ELBO regularizer. The regularizer is the easiest practical instantiation of a broader framework: use variational proxies for diffusion policy gradients, but actively maintain the conditions under which those proxies can be trusted.
There are several natural directions from here. One is to design better schedules for interleaving self-distillation and policy updates. Another is to implement a more sophisticated interleaving and study the interaction of self-distillation and policy gradient. More broadly, the same principle should apply to other generative policies trained through variational objectives, not only diffusion language models.
Reference
[1] Haozhe Jiang, Haiwen Feng, Jiantao Jiao, Angjoo Kanazawa and Nika Haghtalab. Diffusion Policy Optimization without Drifting Apart. https://arxiv.org/abs/2606.13795.
[2] David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng and Angjoo Kanazawa. Flow Matching Policy Gradients. arXiv preprint arXiv:2507.21053, 2025.
[3] Chenyu Wang, Paria Rashidinejad, DiJia Su, Song Jiang, Sid Wang, Siyan Zhao, Cai Zhou, Shannon Zejiang Shen, Feiyu Chen, Tommi Jaakkola and others. SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models. arXiv preprint arXiv:2510.09541, 2025.
[4] Siyan Zhao, Devaansh Gupta, Qinqing Zheng and Aditya Grover. d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning. arXiv preprint arXiv:2504.12216, 2025.
[5] Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen and Chongxuan Li. Large Language Diffusion Models. arXiv preprint arXiv:2502.09992, 2025.
[6] Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer and Ricky T. Q. Chen. Adjoint Matching: Fine-tuning Flow and Diffusion Generative Models with Memoryless Stochastic Optimal Control. ICLR, 2024.
[7] Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov and Sergey Levine. Training Diffusion Models with Reinforcement Learning. arXiv preprint arXiv:2305.13301, 2023.
[8] Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai and Max Simchowitz. Diffusion Policy Policy Optimization. arXiv preprint arXiv:2409.00588, 2024.
[9] Zhihui Xie, Jiacheng Ye, Lin Zheng, Jiahui Gao, Jingwei Dong, Zirui Wu, Xueliang Zhao, Shansan Gong, Xin Jiang, Zhenguo Li and others. Dream-Coder 7B: An Open Diffusion Language Model for Code. arXiv preprint arXiv:2509.01142, 2025.
[10] Xiaohang Tang, Rares Dolga, Sangwoong Yoon and Ilija Bogunovic. wd1: Weighted Policy Optimization for Reasoning in Diffusion Language Models. arXiv preprint arXiv:2507.08838, 2025.